指令集
常见的机器码或者汇编指令可以分成五大类:
- 算术类指令:加减乘除
- 数据传输类指令:给变量复制、在内存里读写数据
- 逻辑类指令:逻辑上的与或非
- 条件分支类指令:if/else
- 无条件跳转指令:函数跳转
不同的 CPU 有不同的指令集,也就对应着不同的汇编语言和不同的机器码,因此在不同的CPU上面编译出来的程序不能在其他CPU上运行,另外汇编语言最终会被汇编成二进制的机器码
这里给出一个简单的MIPS CPU指令集:
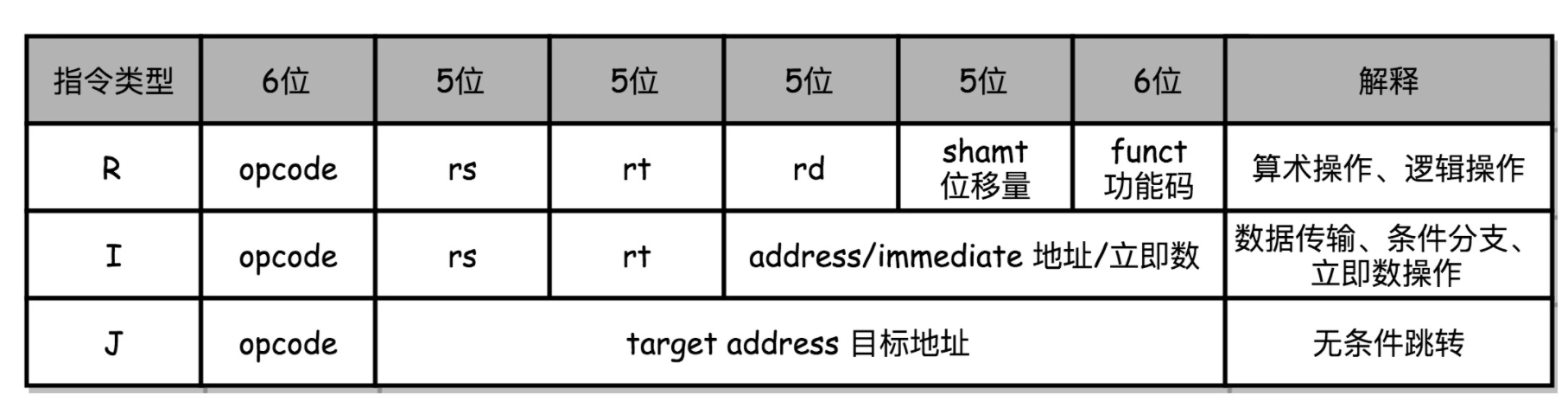
可以看出在MIPS CPU指令集中,每一条指令都是定长的32位整数(Intel指令集则是变长的),因此可以很方便地使用孔带来描述对应的指令,其中打孔了代表1,没打孔代表0,并用4行8列来表示一条指令,一列4行代表一个十六进制数,8列对应32个bit也即8个十六进制数从而对应一条指令
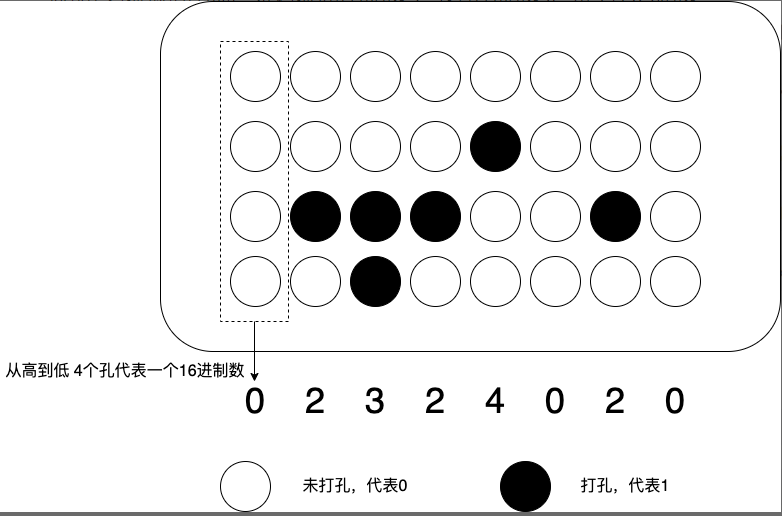
因此远古时代的打孔卡计算机其实就是一种存储程序型计算机,只是这整个程序的机器码,不是通过计算机编译出来的,而是由程序员,用人脑“编译”成一张张卡片的。对应的程序,也不是存储在设备里,而是存储成一张打好孔的卡片。但是整个程序运行的逻辑和其他 CPU 的机器语言没有什么分别,也是处理一串“0”和“1”组成的机器码而已。
编译
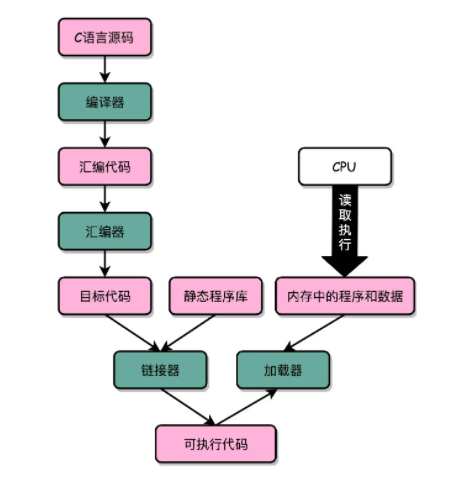
"C 语言代码 - 汇编代码 - 机器码" 这个过程,在我们的计算机上进行的时候是由两部分组成的:
- 第一个部分由编译(Compile)、汇编(Assemble)以及链接(Link)三个阶段组成。在这三个阶段完成之后,才生成了一个可执行文件。
- 第二部分通过装载器(Loader)把可执行文件装载(Load)到内存中,CPU 从内存中读取指令和数据,来开始真正执行程序。
ELF格式和链接
程序最终是通过装载器变成指令和数据的,所以生成的可执行代码也并不仅仅是一条条的指令。通过 objdump 指令,把可执行文件的内容拿出来看,可以发现可执行代码相较于之前的目标代码长得差不多但是长了很多,这是因为在Linux 下,可执行文件和目标文件所使用的都是一种叫 ELF(Execuatable and Linkable File Format)的文件格式,这里面不仅存放了编译成的汇编指令,还保留了很多别的数据。
ELF 文件格式把各种信息,分成一个一个的 Section 保存起来。ELF 有一个基本的文件头(File Header),用来表示这个文件的基本属性,比如是否是可执行文件,对应的 CPU、操作系统等等。除了这些基本属性之外,大部分程序还有这么一些 Section:
- .text Section,也叫作代码段或者指令段(Code Section),用来保存程序的代码和指令;
- .data Section,也叫作数据段(Data Section),用来保存程序里面设置好的初始化数据信息;
- .rel.text Secion,叫作重定位表(Relocation Table)。重定位表里,保留的是当前的文件里面哪些跳转地址是在链接发生之前不知道的。
- .symtab Section,叫作符号表(Symbol Table)。符号表保留了当前文件里面定义的函数名称和对应地址。
最后链接器会扫描所有输入的目标文件,然后把所有符号表里的信息收集起来,构成一个全局的符号表。然后再根据重定位表,把所有不确定要跳转地址的代码,根据符号表里面存储的地址,进行一次修正(也就是所谓的符号重定位,这是链接的核心)。最后,把所有的目标文件的对应段进行一次合并,变成了最终的可执行代码。这也是为什么,可执行文件里面的函数调用的地址都是正确的。
因此同样一个程序,在同类型的CPU上,在Linux下可以执行然而在Windows下却不能执行,其原因就是两个操作系统的可执行文件的格式不一样,Linux下是刚刚讲的ELF,而Windows下就是PE了,Linux 下的装载器只能解析 ELF 格式而不能解析 PE 格式。但是如果我们有一个可以能够解析 PE 格式的装载器,我们就有可能在 Linux 下运行 Windows 程序了。而Linux 下著名的开源项目 Wine,就是通过兼容 PE 格式的装载器,使得用户能直接在 Linux 下运行 Windows 程序的。而现在微软的 Windows 里面也提供了 WSL,也就是 Windows Subsystem for Linux,它可以解析和加载 ELF 格式的文件。
静态链接和动态链接
在Linux下静态链接库和动态链接库分别是.a和.so而在Windows下则分别是.lib和.dll,不管是静态链接库还是动态链接库它们的目的都是为了链接去确定那些在编译时不清楚的函数或变量的地址,而它们的区别如下:
静态链接库
之所以称为静态链接库,是因为在链接阶段链接器就会将汇编生成的目标文件.o与引用到的库一起链接打包到可执行文件中,也就是在链接时完成了符号重定位。其实一个静态库可以简单看成是一组目标文件(.o/.obj文件)的集合,即很多目标文件经过压缩打包后形成的一个文件。静态库特点如下:
- 静态库对函数库的链接是放在编译时期完成的。
- 程序在运行时与函数库无关,移植方便。
- 浪费空间和资源,所有相关的目标文件与牵涉到的函数库都被链接合成一个可执行文件。
动态链接库
动态链接库在程序编译时并不会被链接到目标代码中,而是在程序运行是才被载入。不同的应用程序如果调用相同的库,那么在内存里只需要有一份该共享库的实例,规避了空间浪费问题。同时动态链接库在程序运行是才被载入,也解决了静态库对程序的更新、部署和发布页会带来麻烦,用户只需要更新动态库即可从而避免了静态库更新导致的重新编译与全量更新的问题。动态库特点如下:
- 动态库把对一些库函数的链接载入推迟到程序运行的时期。
- 可以实现进程之间的资源共享。(因此动态库也称为共享库)。
可以看出动态链接库的符号重定位并不是在链接时完成的,那么如何解决符号重定位问题呢?目前Linux 下 ELF 主要支持两种方式:加载时符号重定位及地址无关代码
程序执行过程
寄存器
抛开CPU上几百亿的晶体管是怎么通过电路运转起来的,逻辑上我们可以认为,CPU其实就是由一堆寄存器组成的,而寄存器本质上是由多个触发器或者锁存器组成的简单电路,这个暂且不表
一个CPU里面会有很多种不同功能的寄存器,其中比较特殊的包括三个:
- PC寄存器:用来存放下一条需要执行的计算机指令的内存地址
- 指令寄存器:用来存放当前正在执行的指令
- 条件码寄存器:用一个一个标记位存放CPU进行算术或者逻辑计算的结果,比如a == b的结果,该条件码寄存器往往用来做J类指令的跳转依据
除了上述特殊的寄存器,CPU 里面还有更多用来存储数据和内存地址的寄存器:
- rbp:指向当前栈帧的栈底地址
- rsp:指向栈顶元素
顺序/跳转执行
一个程序执行的时候,CPU 会根据 PC 寄存器里的地址,从内存里面把需要执行的指令读取到指令寄存器里面执行,然后根据指令长度自增,开始顺序读取下一条指令。可以看到,一个程序的一条条指令,在内存里面是连续保存的,也会一条条顺序加载,而有些指令,比如J类指令则会修改PC寄存器里面的地址值,从而达到函数调用、跳转等功能,而if...else..,while/for等程序控制流程,转换为汇编其实就是J类指令进行goto跳转
函数调用
程序函数的调用是基于call和ret指令实现的,并且通过栈和栈帧(rbp,rsp)来进行管理的(这里需要注意的是,该栈帧模型是通过rbp和rsp两个寄存器模拟出来的栈实现的,它相当于直接运行在cpu上,这和Java的栈帧模型是不同的,Java的栈帧是运行在JVM上并由JVM定义,而JVM只是运行在操作系统上的一个进程而已):
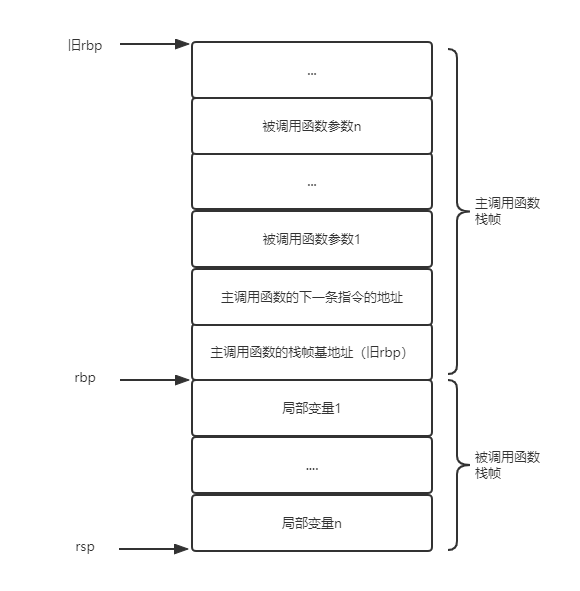
- 函数调用前:主调用函数会将被调用函数中声明的参数表以逆序压栈(方便被调用参数通过索引的方式结合ebp获取对应的函数参数),然后调用call指令再将应该顺序执行的下一条指令所在地址压入栈中,并jmp到对应的被调用函数的地址
- 函数调用中:被调用函数的开头会通过
push rbp去保存主调用函数栈帧的栈底地址(也就是说每次函数调用除了要记录返回地址还要记录原栈帧的栈底地址,另外被调用函数的入参并不属于其栈帧)再通过mov rbp, rsp更新被调用函数栈帧的栈底地址,然后在被调用函数的执行期间,在其栈帧中会根据局部变量的声明顺序将局部变量压栈,因此在被调用函数执行期间,局部变量总是通过将rbp减去偏移量来访问,而函数参数总是通过将rbp加上偏移量来访问的 - 函数调用结束前:当被调用函数执行结束时首先会通过
add rsp, xxx销毁局部变量并将栈顶指针指回rbp,然后通过pop rbp恢复主调用函数栈帧的栈底地址,最后通过ret命令将原来保存的下一条指令出栈进入PC寄存器并执行从而回到主调用函数的函数体中 - 函数调用结束后:此时已经回到了主调用函数的函数体中,主调用函数会通过
add rsp, xxx清理之前为被调用函数入栈的函数参数从而恢复栈帧,然后顺序执行后续指令
函数内联
由于每次函数调用都会涉及到call,ret指令以及出栈和入栈的操作,因此对于一些没有调用其他函数的叶子函数,我们可以通过函数内联的方式进行优化,所谓的函数内联就是直接将函数体替换掉call指令,当然内联也并不是没有代价的内联意味着,我们把可以复用的程序指令在调用它的地方完全展开了。如果一个函数在很多地方都被调用了,那么就会展开很多次,整个程序占用的空间就会变大了。
参考
- 《深入浅出计算机组成原理》
- 《编码:隐匿在计算机软硬件背后的语言》
- Coursera-北京大学-《计算机组成》
- 《程序员的自我修养——链接、装载与库》